Objective of this work:
Created a model which is able to predict COVID-19 related fake news in multiple languages without any need for COVID specific parallel data.
Have a model which is much smaller in size, therefore has the ability to do fast inference (even on a smartphone).
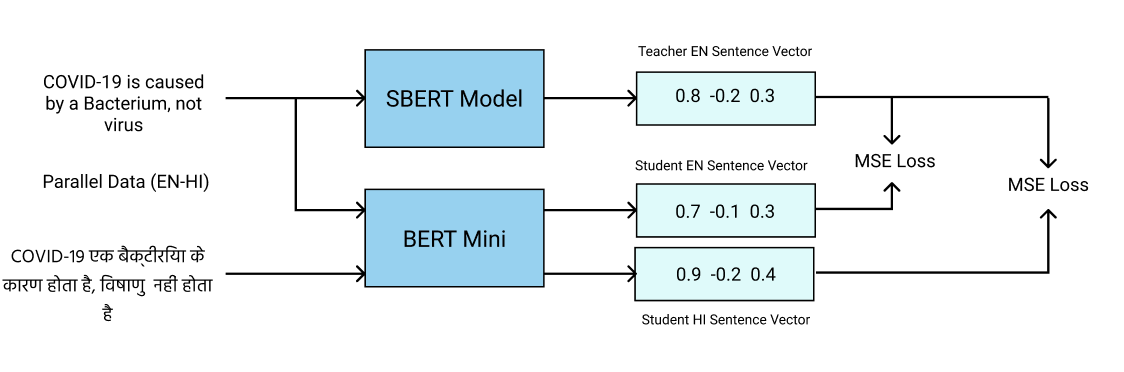
Approach Finetuned a smaller architecture (1) BERT model (L=4, H=512) using labels from a larger model (Sentence BERT) using Knowledge Distillation Ensured (2)shared embedding space between languages and (3)also learn the rich semantics of a larger SBERT model, which are very effective in sentence level classification tasks.</p>
Results
- Because of (1) that we had a much faster inference time: 93.7% reduction (0.495 sec to 0.031 sec)
- Because of (2) the accuracy in hindi was increased by ~35% (0.63 -> 0.845)
- Because of (3) we got a side benefit - accuracy in english was increased by ~6%
This work got accepted in the AI4SG Workshop in IJCAI 2021
Slides - https://docs.google.com/presentation/d/1GNdTsntJjyAI1lX052_lIkPFLJ2UemTUjUgVrq-eGws/edit#slide=id.p1